
基础知识:多模态推理:先看见证据,再组织推理
这篇文章只回答一个问题:一个模型同时看到文字、图片、视频、音频和工具结果时,怎样把这些输入变成可靠判断,而不是把“看起来会描述”误读成“真的会推理”。
多模态推理的核心链路可以拆成五步:感知证据、模态对齐、连接到语言/策略空间、在 token 预算内组织中间状态、用工具或验证器校验输出。任何一步错了,后面的 CoT 写得再漂亮也可能只是围绕错误证据编故事。
第一件事:对齐不是推理
CLIP 是理解多模态模型的好入口,因为它把图像和文本放进同一个 embedding 空间:匹配的图文靠近,不匹配的图文远离。
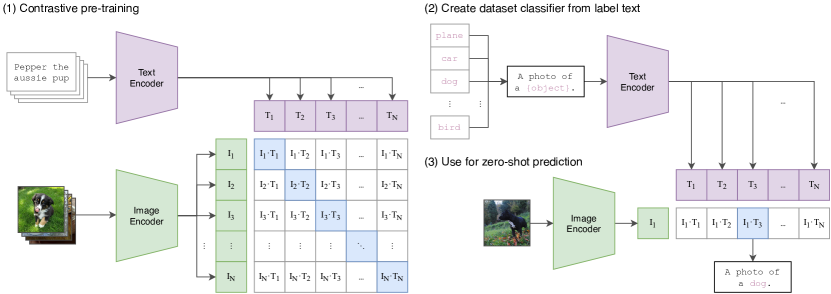
图源:Learning Transferable Visual Models From Natural Language Supervision,Figure 1。原图展示 CLIP 用大量 image-text pairs 做对比预训练,再把类别写成文本 prompts 做 zero-shot prediction。本站用这张图说明:图文对齐给模型一个“图片像哪句话”的语义接口,但它不等于时序理解、工具推理或动作规划。
如果图像 embedding 是 ,文本 embedding 是 ,CLIP 常用归一化后的相似度来比较二者:
这里 越高,表示图像和文本在语义空间里越接近。对比学习会让正确图文对的相似度更高,让错误配对更低。这个机制非常适合开放类别识别、图文检索和视觉语义底座,但它只回答“这张图和哪段文字更匹配”。它不回答“物体接下来会怎么动”“工具结果能不能信”“这一步推理是不是引用了真实证据”。
所以读多模态模型时,第一条边界要立住:看见语义不等于完成推理。一个模型能说出“图里有一个红杯子”,不代表它知道杯口朝向、夹爪距离、杯子是否装满水,也不代表它能安全执行抓取。
第二件事:连接器决定哪些证据进入模型
现代 VLM 通常不是直接把所有像素交给 LLM,而是先用视觉 encoder 得到特征,再通过 connector 变成语言模型可读的 token 或 hidden states。连接器可以是线性 projector、Q-Former、Perceiver Resampler、cross-attention adapter,也可以是更复杂的多模态融合模块。
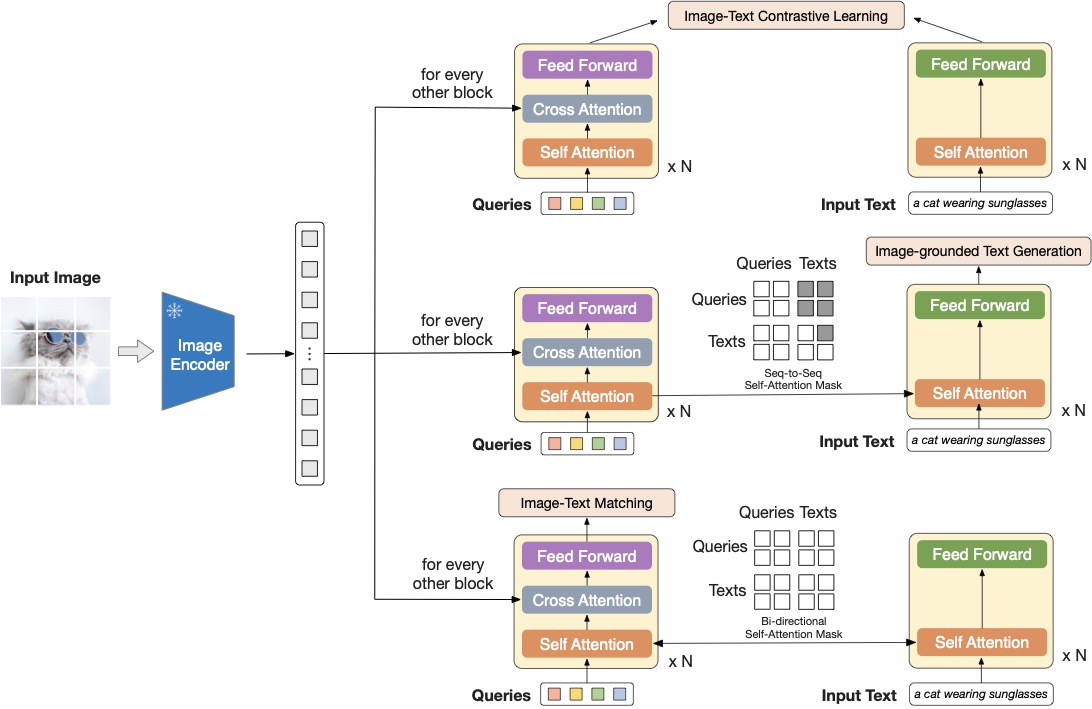
图源:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,Figure 2。原图展示冻结视觉 encoder,通过 Q-Former 的 query tokens 从视觉特征中抽取信息,并分别服务图文对比、图文匹配和 image-grounded generation。本站用这张图说明:connector 是信息瓶颈,它决定 LLM 最终能读到哪些视觉证据。
可以把连接器看成一个证据压缩器:
这里 是图像或视频帧, 是视觉 encoder, 是视觉特征, 可以是一组可学习 query tokens, 是 connector, 是送进 LLM 的视觉证据, 是文本 token。公式想表达的是:LLM 并没有直接读原图,它读的是 connector 压缩后的证据。
这会带来一个很实际的判断:如果 connector 只保留“红杯”这种语义,问答可能正确;但如果任务需要杯口边缘、遮挡、刻度、小字、时间顺序或接触几何,压缩后的 可能已经丢掉关键证据。很多多模态幻觉不是语言模型最后一步突然乱说,而是前面进入语言空间的证据已经不够。
第三件事:多模态 token 预算会改写问题
文本 prompt 的 token 密度通常低;图像、视频和音频的 token 密度高得多。一个视频输入如果按相机、帧、patch 展开,长度会很快爆炸:
如果 Cams=4、Frames=16、每帧 Patches=256,那么视觉 token 就是:
这还没有加文字、工具结果、历史对话、动作状态和思考 token。完整上下文更像:
这里每一项都在抢同一个上下文窗口和同一笔 KV cache。音频如果保留细粒度时间特征,视频如果保留高分辨率 patch,工具如果返回整页日志,CoT 如果无限展开,最后不是“信息更多”,而是注意力稀释、延迟上升、关键证据被截断。
因此多模态系统常常要做取舍:
| 压缩动作 | 省下什么 | 可能丢什么 |
|---|---|---|
| 图像降分辨率 | 视觉 token、prefill 成本 | 小字、细小物体、接触边缘 |
| 视频抽帧 | 时间 token、KV cache | 快速动作、因果顺序、短暂事件 |
| audio token 降采样 | 长音频上下文 | 语气、停顿、背景声细节 |
| query/resampler 压缩 | LLM 输入长度 | 空间几何和局部证据 |
| 工具结果摘要 | 上下文预算 | 原始证据、异常日志、边界条件 |
| shorter thinking | decode 延迟 | 复杂任务的中间检查空间 |
多模态推理不是简单地“把所有模态都塞进来”。更成熟的做法是先判断任务需要哪类证据:读表格要 OCR 和布局,视频问答要时间定位,机器人动作要几何和接触,语音对话要语义、说话人状态和时间节奏。证据类型不同,token 分配就应该不同。
第四件事:CoT 是工作区,不是证据本身
Chain-of-Thought 的价值在于给复杂任务留出中间工作区:列条件、分解问题、做计算、比较候选、检查矛盾。经典 CoT prompting 论文证明,在数学和符号推理任务中,中间推理样例能显著改善模型表现;Self-Consistency 进一步把“采样多条推理路径再聚合答案”变成一种 test-time search。
但多模态任务里,CoT 的第一步往往不是推导,而是证据定位。比如用户上传一张工厂面板照片问“能不能启动”,可靠流程应该先确认急停按钮、报警灯、压力表、屏幕提示和操作条件;如果第一步把报警灯颜色看错了,后面的推理只会更流畅地错下去。
可以把多模态推理写成:
这里 是感知证据, 是用户问题, 是上下文或工具结果, 是中间推理, 是最终回答。这三行式子强调一件事:推理 应该依赖证据 ,最终回答也应该能回指证据。没有证据的长解释不是可靠性,最多是语言流畅性。
产品系统也不一定要暴露完整内部 CoT。更有用的是暴露可复核的外部形态:关键观察、引用来源、工具调用结果、计算步骤、置信边界和下一步建议。完整内部草稿可以服务训练和调试,但面向用户时,可靠性来自证据和验证,而不是解释越长越好。
第五件事:工具和验证器改变的是搜索过程
复杂任务经常不能只靠模型内部状态完成。视觉模型可能需要 OCR 工具,代码任务需要运行测试,事实问答需要检索,数学题可以调用计算器,机器人任务需要状态估计和安全规则。
ReAct 的重要性在于把 reasoning 和 acting 交替起来:
1 | 观察问题 |
多候选推理可以写成:
这里 是验证器,可以是单元测试、规则检查、检索证据匹配、reward model、OCR 结果一致性,也可以是人审。这个过程不是让 base model 突然看见更多世界,而是把“生成一次答案”改成“搜索多个候选,并用更接近任务的信号筛选”。
验证器也有边界。OCR 会错,检索会漏,judge model 会偏,工具结果里可能有 prompt injection,机器人传感器也会漂移。因此工具返回必须被当作证据读取,而不是当作更高优先级的新指令;验证器通过了,也只说明它覆盖的条件通过了。
怎么判断一篇多模态/CoT 论文有没有讲清楚
读这类论文,不要只看 benchmark 表。更重要的是看它有没有交代证据链。
| 论文说法 | 应该追问 |
|---|---|
| 支持图像、视频、音频 | 每种模态如何 token 化,token 密度是多少 |
| 视觉接入 LLM | connector 是 projector、query、cross-attention 还是 resampler,丢了哪些信息 |
| 支持 reasoning / thinking | thinking 是 prompt、SFT、RL、蒸馏还是 test-time search |
| 支持 tool use | 工具结果如何进入上下文,是否有注入防护和失败恢复 |
| 多模态 benchmark 提升 | 是看对了、想对了、还是数据格式更像训练集 |
| 长上下文能力强 | 关键证据在长输入中是否能被定位,而不是只看 needle retrieval |
| 可解释 | 解释是否绑定证据,还是只生成顺滑理由 |
一个系统如果没有区分“看错了”和“想错了”,就很难改。看错了通常要改数据、分辨率、OCR、视觉 encoder、connector 或证据定位;想错了才更多涉及 CoT、工具、验证器、训练目标和 reward。
一个完整例子:图片问答到可靠诊断
假设用户上传一张设备面板照片,问“现在是否可以启动”。一个脆弱系统会直接回答“可以”或“不可以”。一个更可靠的多模态推理系统会拆成四层:
| 层 | 要做什么 | 失败时怎么暴露 |
|---|---|---|
| 感知 | 读出急停按钮、报警灯、压力表、屏幕文字 | 标出无法确认的小字或遮挡区域 |
| 对齐 | 把观察和启动条件对应起来 | 明确哪个条件由哪条观察支撑 |
| 推理 | 判断是否满足启动规则 | 区分“证据不足”和“条件不满足” |
| 验证 | OCR 复核、规则校验、请求补拍或人工确认 | 不把高风险结论伪装成确定答案 |
这种回答可能没有最长 CoT,但更可靠,因为它把证据、规则和不确定性分开了。多模态推理的成熟标志不是模型能写出很长分析,而是它知道自己在用哪些证据,以及哪些证据还没看清。
读完以后怎么判断
多模态推理的基础不是“图片接上 LLM”或“让模型多写 CoT”,而是证据链:视觉、音频、视频和工具结果先被编码和压缩,connector 决定哪些证据进入语言空间,token 预算决定哪些细节能留下,CoT 负责组织复杂约束,工具和验证器负责补外部事实与可执行检查。可靠性来自这条链路的每一环,而不是来自任意一个模型能力标签。
外部精读
- CLIP:理解图文对齐和 zero-shot transfer 的基础。
- The Illustrated CLIP:用图讲清相似度矩阵和文本分类器构造。
- BLIP-2:理解 Q-Former 作为视觉证据瓶颈。
- Flamingo:理解 cross-attention 和 Perceiver Resampler 如何让 LLM 读取视觉信息。
- LLaVA:理解视觉指令微调如何把 VLM 推向对话式使用。
- Chain-of-Thought Prompting:理解中间推理样例为什么能改善复杂任务。
- ReAct:理解推理和工具行动如何交替。
- MMMU:理解多学科多模态推理评测为什么要覆盖证据定位与知识推理。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:多模态推理:先看见证据,再组织推理
- Author: Charles
- Created at : 2025-06-23 09:00:00
- Updated at : 2025-06-23 09:00:00
- Link: https://charles2530.github.io/2025/06/23/ai-files-foundations-multimodal-cot-and-reasoning-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.