
VLM/VLA:视频表征、状态记忆与长时序压缩
VLM 从图片开始,世界模型却必须处理时间。对 VLA 和世界模型来说,视频不是很多张图片的拼接,而是状态如何随动作、接触、遮挡和环境变化而演化。
核心问题
视频表征和长时记忆要回答的是:哪些短时视觉变化应该被压成当前状态,哪些长期事件必须写进记忆,才能让模型在遮挡、接触和长任务里不丢关键变量。
静态 VLM 可以把一张图说清楚;VLA 和世界模型还要知道杯子刚才有没有被抓住、是否被放到遮挡区、哪个动作造成了状态变化、下一步是否需要恢复。视频表征如果只会做短 clip 理解,不会把关键事件写进可持续状态,就很难支撑闭环控制。
视频表征的四个目标
| 目标 | 读者要看什么 | 对世界模型的意义 |
|---|---|---|
| 时序连续性 | 物体是否跨帧一致 | 决定 rollout 是否漂移 |
| 运动与接触 | 速度、碰撞、抓取、遮挡 | 决定动作后果是否可信 |
| 长时记忆 | 早期状态是否影响后续决策 | 决定长任务能否恢复 |
| token 压缩 | 多帧信息如何不爆上下文 | 决定训练成本是否可控 |
一个最小状态编码可以写成:
这行式子把最近 步观测压成当前状态 。它适合描述短时窗口,但也暴露了问题:长任务里,早期发生的关键事件可能已经不在 里。如果不写入 memory,模型会忘记被遮挡物体、已完成阶段和失败原因。
常见路线
1. 帧级 VLM 拼接
把关键帧抽出来送进 VLM,是最容易落地的方案。它适合视频问答、事件摘要和低频观察,但对机器人控制和世界模型不够:帧间速度、接触瞬间和动作结果可能被采样漏掉。
2. 视频 encoder / latent prediction
用视频 encoder 直接学习时空特征,再在 latent space 做预测。V-JEPA、JEPA 类方法的启发在于:不必重建所有像素,先学能表达运动和上下文的 latent。
这对高效训练很重要,因为像素级重建昂贵且容易把容量花在纹理上;latent prediction 更容易把学习压力放到对象、运动和结构上。
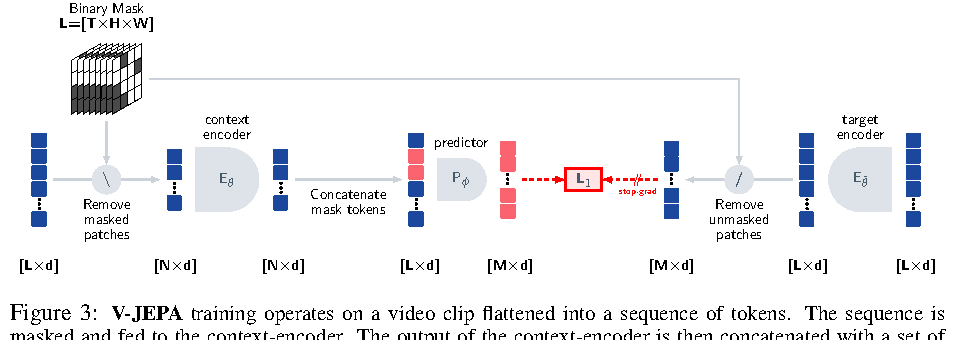
图源:V-JEPA: Latent Video Prediction for Visual Representation Learning,Figure 3。原论文图意:context encoder 只处理 masked video 中可见 token,predictor 结合 context output 和 mask tokens 去预测 target encoder 对完整视频产生的 masked token representations。
这张图先看 context encoder:它只处理未遮挡 token;predictor 再去预测被 mask 的时空区域 latent。V-JEPA 支撑的是状态学习,而不是像素复读:模型可以学习对象、运动和上下文结构,不必把容量全花在纹理上。但它不带动作条件、reward、risk 和 planner 接口,所以还不是完整世界模型。它能帮助状态理解“红杯在一段视频中持续存在”,但还不能单独回答“快速移动会不会滑落”。
V-JEPA 这类 latent prediction 可以粗略写成:
这里 是可见上下文的表示, 是 mask 位置或 mask token, 是模型预测的被遮挡区域表示。它预测的是 latent,不是动作条件未来。要进入 VLA 或 world model,还要加入 、reward、risk 和闭环验证。
3. 记忆层级
长视频不能把所有帧都放进上下文。更现实的做法是分层:
| 层级 | 保存什么 | 代价 |
|---|---|---|
| 当前窗口 | 最近几帧、动作、局部状态 | 高保真但昂贵 |
| 工作记忆 | 目标、约束、关键物体状态 | 结构化但可能漏细节 |
| 长期记忆 | 地图、任务历史、失败记录 | 便宜但读取慢 |
| 回放库 | 完整轨迹、传感器日志 | 不进实时上下文,供训练和复盘 |
与高效训练的关系
视频世界模型训练很容易被三件事拖垮:
- 帧数太多,序列长度爆炸。
- 分辨率太高,视觉 token 爆炸。
- 目标太像像素重建,模型学到纹理多于动态。
因此高效训练通常会组合使用:视频 tokenizer、latent prediction、patch / sequence packing、mask 建模、动作条件压缩、长短 horizon 混合训练,以及按任务价值采样轨迹。
VLA 场景下的状态问题
机器人任务里,一个状态是否好,不只看能不能回答画面问题,还要看:
- 抓取前后物体是否被持续跟踪。
- 遮挡后物体是否仍被记住。
- 接触发生时是否保留关键瞬间。
- 动作失败后是否知道失败原因。
- 同一任务在不同相机和机器人上是否能对齐。
这些能力决定 VLA 能不能从“看一眼做一步”走向“执行、观察、恢复、继续”。
一个记忆写入例子:杯子被移到遮挡区
下面是一条 episode 中最容易被短窗口模型遗忘的片段。关键不是把所有帧都长期保存,而是把会改变后续决策的状态写入工作记忆。
| 时间 | 观测 | 动作 | 应写入的 memory | 后续用途 |
|---|---|---|---|---|
| 红杯在桌面左前方,无遮挡 | 机械臂接近 | object:red_cup pose=left_front visible=true |
建立对象身份 | |
| 夹爪接触杯把 | 闭合夹爪 | contact:red_cup handle grasped=true confidence=0.82 |
判断是否已抓住 | |
| 杯子被移动到箱子后方,部分遮挡 | 放置动作 | object:red_cup pose=behind_box visible=false last_seen=t42 |
遮挡后仍保留去向 | |
| 当前画面只看到箱子 | 继续整理桌面 | task_state:red_cup already_moved=true |
避免重复抓取原位置 |
如果只保留最近 8 帧, 时模型可能看不到杯子,就把它预测回训练集中最常见的桌面位置。一个更稳的世界模型会把“物体已被移动”和“最后可信位姿”作为结构化 memory token 或 latent state 持续携带。
memory token 不是摘要作文
长时记忆不是把视频写成自然语言摘要就结束。对 VLA / 世界模型更有用的是可验证字段:
1 | memory_event: |
这些字段可以直接进入训练:last_pose_base 用于几何一致性,action_caused_by 用于动作敏感性,confidence 用于风险头或不确定性校准。自然语言摘要适合给人看,结构化记忆才适合给模型、planner 和评测脚本消费。
一个记忆更新可以用极简形式写成:
这行式子把记忆更新写成四个输入:旧记忆 、当前状态 、刚才动作 、发生的事件 。如果执行 place_chunk_04 后红杯被箱子遮挡,memory 应写入“红杯最后在托盘后方,当前不可见,但已移动过”。关键不是把视频写成摘要作文,而是让后续策略和评测脚本能读到可验证状态。
硬证据模块:记忆页要证明“长时状态没有漂”
视频记忆的证据不能只靠几帧可视化。世界模型真正要证明的是:压缩后的状态在动作、遮挡和长任务里仍保留可决策变量。
| 证据项 | 最小可复算例子 | 失败案例 | 验收指标 |
|---|---|---|---|
| 本页解决哪项成本 | 当前窗口 token + memory token 替代全视频上下文 | memory 写错后污染后续 rollout | memory token 数、context length、读取命中率 |
| 长时一致性 | 2s/8s/30s horizon 下对象位置和 ID 曲线 | 物体被遮挡后身份重置 | object permanence、latent drift |
| 动作因果 | action_caused_by 字段能否解释状态变化 |
记忆知道物体移动了,但不知道由哪个动作造成 | action-conditioned event accuracy |
| 风险校准 | 遮挡、滑落、接触前后 risk 是否上升 | 风险在关键接触帧前没有抬头 | near-miss recall、risk ECE |
| 证据边界 | 说明结果来自 replay、ablation 还是闭环 | 只在离线 replay 保住,闭环仍重复抓取 | closed-loop recovery rate |
最小失败 replay 应记录三件事:最后可信观测、写入 memory 的字段、后续动作选择。若模型在 wrong_target_after_occlusion 中选择了可见诱饵,问题可能不是动作头,而是 memory 没有保住被遮挡目标的身份和最后位置。
评测建议
视频表征至少要补三类专项评测:
| 评测 | 例子 | 看什么 |
|---|---|---|
| 时间一致性 | 物体进出遮挡后是否仍识别 | 物体持久性 |
| 动作敏感性 | 同一画面接不同动作,未来是否分叉 | action conditioning |
| 长时恢复 | 第 1 步约束在第 20 步是否仍有效 | 记忆保真 |
真实排查案例:短视频指标好,长任务中忘了物体在哪里
| 环节 | 观察 |
|---|---|
| 输入症状 | 模型在 2-4 秒短 clip 上预测稳定,但机器人把杯子移到遮挡区域后,后续 rollout 又把杯子预测回原位置 |
| 指标 | short-horizon video loss 正常;object permanence、long-horizon consistency、closed-loop recovery 明显差 |
| Trace / 回放观察 | 当前窗口只保留最近几帧,工作记忆没有记录“杯子已被移动”;遮挡发生后,模型回到训练集中最常见的桌面布局 |
| 判断 | 视频 encoder 学到了局部运动,但没有把关键状态写入可持续记忆;这类错误短 horizon loss 很难暴露 |
| 修复 | 给关键对象建立 memory token;加入遮挡前后身份一致性 loss;把长时失败、回到旧位置、任务阶段遗忘单独成桶回流 |
| 反例 | 如果任务只是短视频问答或短片段摘要,当前窗口可能足够;只有当系统要做长时 VLA 或世界模型 rollout 时,长期状态才变成核心成本 |
如果一个视频表征只在静态识别上好,却不能支撑动作敏感预测,它更适合 VLM,不适合作为世界模型的核心状态。
外部精读
- V-JEPA:理解 latent video prediction 如何学习对象、运动和上下文结构。
- VideoMAE:对照看 masked video autoencoding 与 JEPA-style latent prediction 的差别。
- MemGPT:虽然不是视觉模型,但适合理解工作记忆、长期记忆和上下文管理的系统思想。
- Open X-Embodiment / RT-X:看跨机器人数据中多相机、动作、任务阶段和轨迹历史为什么很难统一。
- DROID:真实机器人长轨迹数据的代表,适合思考哪些事件应该写入 memory。
相关阅读与下一步
- 外部材料:CLIP 论文。
- 外部材料:LLaVA 论文。
- 外部材料:Flamingo 论文。
- 站内下一步:VLM 专题。
- 站内下一步:视觉 Tokenizer 与连接器。
- 站内下一步:多模态评测与失败模式。
- Title: VLM/VLA:视频表征、状态记忆与长时序压缩
- Author: Charles
- Created at : 2026-02-23 09:00:00
- Updated at : 2026-02-23 09:00:00
- Link: https://charles2530.github.io/2026/02/23/ai-files-vlm-video-representation-and-memory/
- License: This work is licensed under CC BY-NC-SA 4.0.