
世界模型:规划即推理与潜在动作
世界模型与规划有一条重要线索:规划不一定只能写成显式搜索或值函数优化,也可以写成推断问题。与此同时,复杂动作空间直接规划太难,很多系统会把动作片段压缩成潜在动作或技能代码,再在更紧凑的空间里做推理。
这页连接三件事:为什么奖励最大化可以改写成后验推断,为什么潜在动作适合高维控制,以及这条路线如何和 WM / WAM / VAM 接起来。
规划为什么可以写成推断
传统控制常写成:
Planning as Inference 会引入“最优性变量” ,把高奖励轨迹视作更高后验概率的轨迹:
一个常见构造是:
于是轨迹后验可写成:
取对数后,奖励项推动轨迹更优,轨迹先验 起到正则化作用。这也是为什么 planning as inference 常和 behavior prior、KL-regularized control、maximum-entropy RL 放在一起讨论。
图源:A Path Towards Autonomous Machine Intelligence,Figure 17。原论文图意:在不确定环境中,latent variables 表达不能从先验观测推出的预测信息;规划时可以采样多条 latent trajectory,并通过均值、方差或风险敏感目标选择动作序列。
难点解释:为什么规划要保留多种未来。
如果世界模型只给一个平均未来,planner 会误以为环境是确定的;但真实场景里可能有遮挡目标、未观测意图或随机干扰。latent variable 让模型保留多条可能轨迹,规划器就能比较“平均收益高但风险大”和“收益略低但更稳”的选择。这也是 planning as inference 比单纯最大化一条 reward 轨迹更自然的地方。
这个视角对世界模型有什么用
世界模型通常已经在学习:
- 状态转移;
- 观测分布;
- reward / cost / risk;
- 隐变量或 belief state。
设隐状态为 ,动作为 。世界模型通常提供三类预测分布:
在此基础上引入最优性变量,规划就可以变成隐状态轨迹上的后验推断。经典 WM 更强调“给定动作后世界怎么变”,planning as inference 进一步问:“在这些世界演化规律之上,什么动作后验最像成功轨迹?”
这个视角的价值是,它天然容纳不确定性、行为先验、约束和部分可观测状态,不必把规划、状态估计和动作先验拆成完全独立的问题。
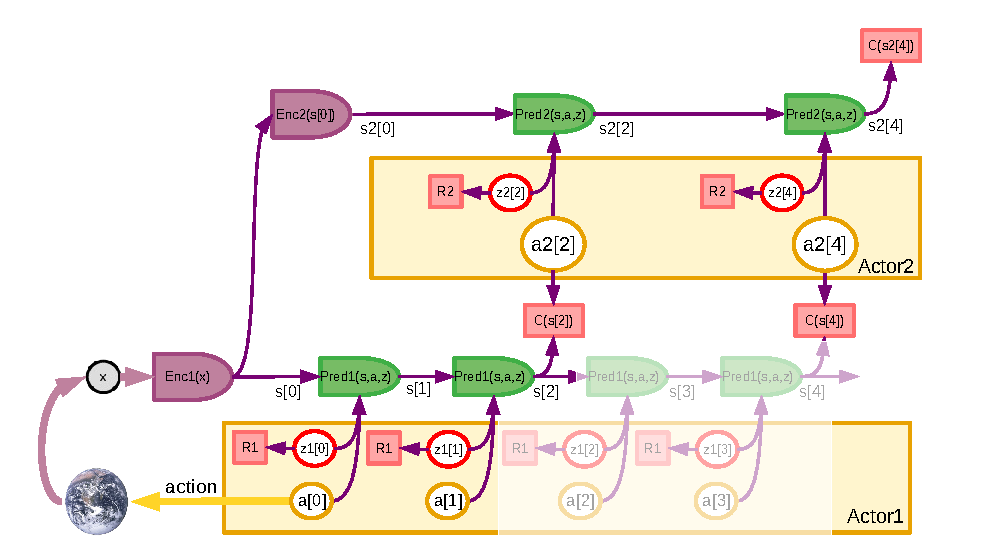
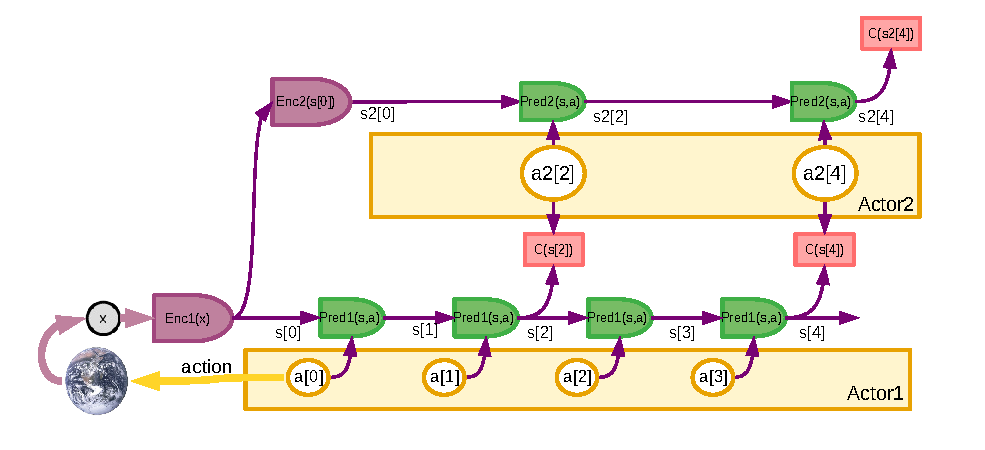
潜在动作为什么必要
真实机器人或复杂 agent 的原始动作空间往往高维、噪声大、短时强相关。机械臂每一步可能包含末端位姿增量、抓手开合、关节速度和力控制参数;网页 agent 的动作可能包含点击、输入、等待、工具调用和状态检查。直接在这些原始动作上做长时搜索,很快会遇到组合爆炸。
潜在动作的想法是:先把动作片段压缩成低维代码 ,再规划:
这样 planner 不必在每个细粒度控制量上搜索,而是在“接近把手”“抓取并提起”“重新观察”“调用工具并检查结果”这类更高层动作单元上推理。
潜在动作的关键要求是:
- 足够紧凑,便于规划;
- 足够可解码,能还原可执行动作;
- 足够有语义,能表达任务阶段和技能;
- 与世界模型 latent 对齐,方便预测动作后果。
图源:A Path Towards Autonomous Machine Intelligence,Figure 16。原论文图意:分层 JEPA / world model 可以在不同抽象层级上预测和规划,高层处理慢变量与目标,低层处理更细的动作和观测。
潜在动作如何学习
常见路线包括:
| 路线 | 做法 | 适合场景 |
|---|---|---|
| VAE 动作片段 | 编码, 解码 | 连续控制、可微优化 |
| 离散技能代码 | tokenizer/codebook 把动作片段离散化 | 高层规划、技能组合 |
| 行为分段 | 从演示中切出技能原语 | 机器人任务、流程型 agent |
| Action chunk | 直接把固定长度动作块当规划单位 | VLA、遥操作学习 |
| World-action latent | 在世界模型 latent 中联合定义动作转移 | WAM/VAM 路线 |
不同路线的取舍在于:连续 latent 更适合梯度优化,离散技能更像程序或 token 组合,action chunk 工程上简单但解释性和复用性较弱。
和 WM、WAM、VAM 的关系
Planning as inference 与潜在动作可以接到三类世界模型上:
- WM:给定候选 latent action,世界模型 rollout 未来状态、reward 和 risk,再由 planner 选择;
- WAM:模型直接联合生成未来动作和未来观测,planner 更像在联合后验中采样;
- VAM:视频 latent 提供时空先验,潜在动作对齐视频变化,用于动作生成或数据合成。
这也是为什么潜在动作是连接经典 world model 和现代 action-conditioned generative model 的桥。它把“世界如何变”和“动作如何组织”放到同一个推理框架里。
工程风险
这条路线常见失败模式包括:
| 风险 | 表现 | 处理方向 |
|---|---|---|
| Latent 不可执行 | planner 找到高分 ,解码动作做不出来 | 加可执行性约束和行为先验 |
| Latent 无语义 | 搜索空间变小但不可控 | 加任务阶段、技能标签或离散代码 |
| World model 偏差 | imagined success 线上失败 | 做模型不确定性和真实回放校验 |
| 长时 rollout 漂移 | 短期可用,长任务崩 | 缩短 horizon、replan、引入风险头 |
| 先验过强 | 模型只会模仿旧行为 | 加反事实数据和探索机制 |
不要只看 imagined return。真正要看的是接入 planner 后的闭环成功率、恢复能力、风险率和系统延迟。
评测清单
评估这类方法时建议同时报告:
- latent action 重建误差和可执行率;
- latent 空间中的任务阶段可分性;
- world model 对不同 latent action 的未来分叉是否合理;
- planner 在固定计算预算下的成功率和风险率;
- replan 频率、单步延迟和 horizon 成本;
- OOD 状态下是否能回退到保守动作;
- 与原始动作搜索、行为克隆和经典 MPC 的对比。
Planning as inference 的价值不在于把控制问题换个数学名字,而在于把奖励、先验、约束、不确定性和动作表示放进同一个概率框架。潜在动作则让这个框架在高维真实动作空间里更可计算。
相关阅读与下一步
- 外部材料:World Models 论文。
- 外部材料:DeepMind Genie 2。
- 外部材料:Meta V-JEPA 2。
- 站内下一步:世界模型专题。
- 站内下一步:RSSM、Dreamer 与规划。
- 站内下一步:世界模型评测与失效模式。
- Title: 世界模型:规划即推理与潜在动作
- Author: Charles
- Created at : 2026-03-12 09:00:00
- Updated at : 2026-03-12 09:00:00
- Link: https://charles2530.github.io/2026/03/12/ai-files-world-models-planning-as-inference-and-latent-actions/
- License: This work is licensed under CC BY-NC-SA 4.0.