
VLM/VLA:视频表征、状态记忆与长时序压缩
VLM 从图片开始,世界模型却必须处理时间。对 VLA 和世界模型来说,视频不是很多张图片的拼接,而是状态如何随动作、接触、遮挡和环境变化而演化。
视频表征要解决“当前发生了什么”和“之前发生的事还留下了什么影响”。如果只把每帧当图片理解,模型很容易会描述画面,却抓不住速度、因果、物体持久性和动作后果。
视频表征的四个目标
| 目标 | 读者要看什么 | 对世界模型的意义 |
|---|---|---|
| 时序连续性 | 物体是否跨帧一致 | 决定 rollout 是否漂移 |
| 运动与接触 | 速度、碰撞、抓取、遮挡 | 决定动作后果是否可信 |
| 长时记忆 | 早期状态是否影响后续决策 | 决定长任务能否恢复 |
| token 压缩 | 多帧信息如何不爆上下文 | 决定训练成本是否可控 |
常见路线
1. 帧级 VLM 拼接
把关键帧抽出来送进 VLM,是最容易落地的方案。它适合视频问答、事件摘要和低频观察,但对机器人控制和世界模型不够:帧间速度、接触瞬间和动作结果可能被采样漏掉。
2. 视频 encoder / latent prediction
用视频 encoder 直接学习时空特征,再在 latent space 做预测。V-JEPA、JEPA 类方法的启发在于:不必重建所有像素,先学能表达运动和上下文的 latent。
这对高效训练很重要,因为像素级重建昂贵且容易把容量花在纹理上;latent prediction 更容易把学习压力放到对象、运动和结构上。
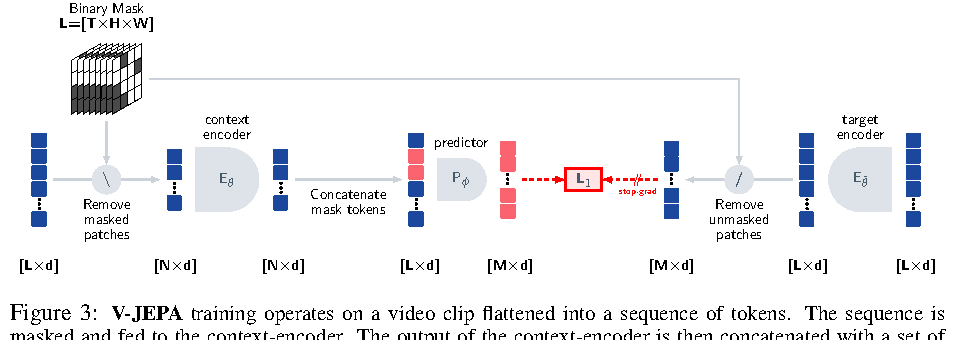
图源:V-JEPA: Latent Video Prediction for Visual Representation Learning,Figure 3。原论文图意:context encoder 只处理 masked video 中可见 token,predictor 结合 context output 和 mask tokens 去预测 target encoder 对完整视频产生的 masked token representations。
V-JEPA 的目标不是把遮挡区域画得多清楚,而是在 latent space 预测被遮挡时空区域的表示。这给世界模型一个重要启发:视频状态应优先保留对象、运动、遮挡和上下文结构,而不是把容量花在纹理复原上。但 V-JEPA 仍缺动作条件、reward、risk 和 planner 接口,所以它更适合作为视频状态学习依据,而不是完整世界模型答案。
3. 记忆层级
长视频不能把所有帧都放进上下文。更现实的做法是分层:
| 层级 | 保存什么 | 代价 |
|---|---|---|
| 当前窗口 | 最近几帧、动作、局部状态 | 高保真但昂贵 |
| 工作记忆 | 目标、约束、关键物体状态 | 结构化但可能漏细节 |
| 长期记忆 | 地图、任务历史、失败记录 | 便宜但读取慢 |
| 回放库 | 完整轨迹、传感器日志 | 不进实时上下文,供训练和复盘 |
与高效训练的关系
视频世界模型训练很容易被三件事拖垮:
- 帧数太多,序列长度爆炸。
- 分辨率太高,视觉 token 爆炸。
- 目标太像像素重建,模型学到纹理多于动态。
因此高效训练通常会组合使用:视频 tokenizer、latent prediction、patch / sequence packing、mask 建模、动作条件压缩、长短 horizon 混合训练,以及按任务价值采样轨迹。
VLA 场景下的状态问题
机器人任务里,一个状态是否好,不只看能不能回答画面问题,还要看:
- 抓取前后物体是否被持续跟踪。
- 遮挡后物体是否仍被记住。
- 接触发生时是否保留关键瞬间。
- 动作失败后是否知道失败原因。
- 同一任务在不同相机和机器人上是否能对齐。
这些能力决定 VLA 能不能从“看一眼做一步”走向“执行、观察、恢复、继续”。
评测建议
视频表征至少要补三类专项评测:
| 评测 | 例子 | 看什么 |
|---|---|---|
| 时间一致性 | 物体进出遮挡后是否仍识别 | 物体持久性 |
| 动作敏感性 | 同一画面接不同动作,未来是否分叉 | action conditioning |
| 长时恢复 | 第 1 步约束在第 20 步是否仍有效 | 记忆保真 |
真实排查案例:短视频指标好,长任务中忘了物体在哪里
| 环节 | 观察 |
|---|---|
| 输入症状 | 模型在 2-4 秒短 clip 上预测稳定,但机器人把杯子移到遮挡区域后,后续 rollout 又把杯子预测回原位置 |
| 指标 | short-horizon video loss 正常;object permanence、long-horizon consistency、closed-loop recovery 明显差 |
| Trace / 回放观察 | 当前窗口只保留最近几帧,工作记忆没有记录“杯子已被移动”;遮挡发生后,模型回到训练集中最常见的桌面布局 |
| 判断 | 视频 encoder 学到了局部运动,但没有把关键状态写入可持续记忆;这类错误短 horizon loss 很难暴露 |
| 修复 | 给关键对象建立 memory token;加入遮挡前后身份一致性 loss;把长时失败、回到旧位置、任务阶段遗忘单独成桶回流 |
| 反例 | 如果任务只是短视频问答或短片段摘要,当前窗口可能足够;只有当系统要做长时 VLA 或世界模型 rollout 时,长期状态才变成核心成本 |
如果一个视频表征只在静态识别上好,却不能支撑动作敏感预测,它更适合 VLM,不适合作为世界模型的核心状态。
- Title: VLM/VLA:视频表征、状态记忆与长时序压缩
- Author: Charles
- Created at : 2026-04-13 09:00:00
- Updated at : 2026-04-13 09:00:00
- Link: https://charles2530.github.io/2026/04/13/ai-files-vlm-video-representation-and-memory/
- License: This work is licensed under CC BY-NC-SA 4.0.