
VLM/VLA:视觉 Tokenizer、连接器与信息瓶颈
VLM/VLA 的第一个工程问题不是“模型够不够大”,而是视觉信息如何进入语言模型或动作模型。图像 patch、视频帧、3D 点云、深度图和相机外参都不能原样无限塞进上下文。必须先把视觉压成 token、latent 或查询结果,再交给后续模型消费。
视觉连接器的本质是信息瓶颈:保留任务需要的信息,丢掉暂时不重要的细节。VLM 关心回答问题,VLA 关心动作可执行,世界模型关心未来可预测性,这三者需要的视觉信息并不完全相同。
三层接口
| 层级 | 典型形式 | 主要问题 | 失败表现 |
|---|---|---|---|
| 视觉 encoder | ViT、CNN、视频 encoder、3D encoder | 如何得到稳定视觉特征 | 小物体漏检、运动模糊、坐标漂移 |
| 连接器 | projector、Q-Former、resampler、cross-attention | 如何控制 token 数和语义密度 | 回答泛泛、定位不准、细节丢失 |
| 消费端 | LLM、policy head、world model latent | 如何服务语言、动作或未来预测 | 会描述但不会行动,或会行动但不能解释失败 |
论文依据:BLIP-2 把连接器做成信息瓶颈
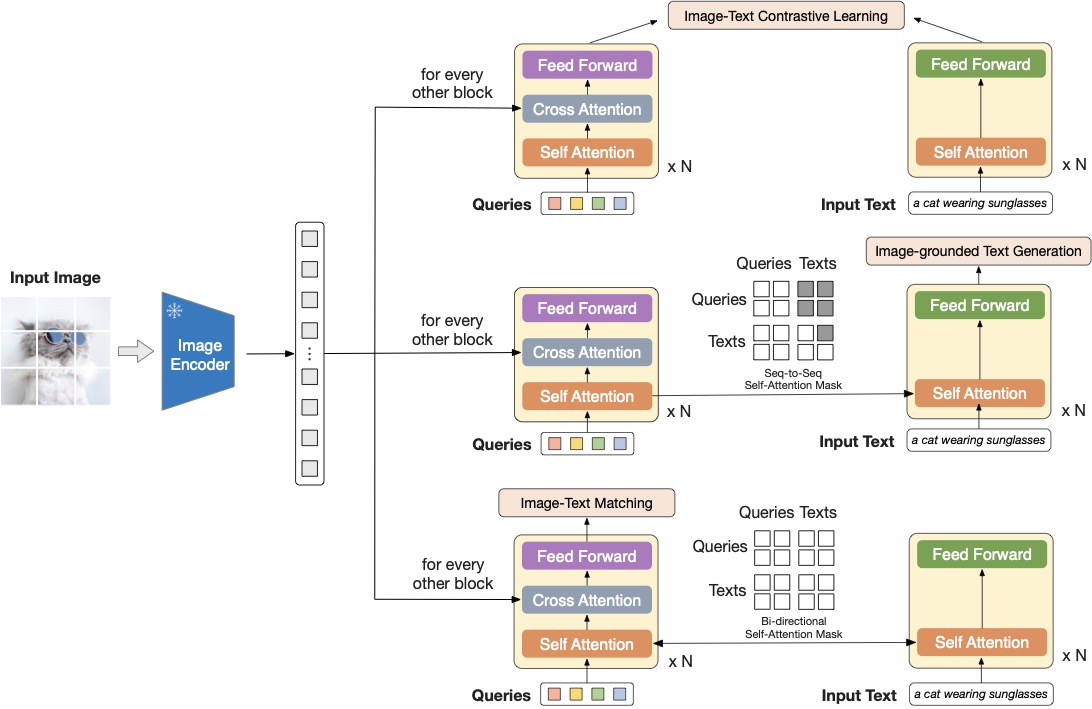
图源:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,Figure 2。原论文图意:冻结图像编码器,用 Q-Former 通过少量 query token 从视觉特征中抽取信息,并分别服务 image-text contrastive learning、image-grounded text generation 和 image-text matching。
这张图的关键是 query token:后续语言模型并不直接吞下所有图像 patch,而是通过一个可训练瓶颈读取视觉证据。放到世界模型高效训练里,问题会更尖锐:VLM 的 query 主要为当前问答服务,世界模型的视觉 latent 还必须保留未来预测、动作后果和风险判断需要的信息。因此连接器不能只按 VQA 分数选,还要按动作敏感性、接触状态和长时记忆验收。
为什么连接器是高效训练关键
视觉 token 太多,会直接放大训练成本:
- 注意力成本随序列长度增加。
- 多帧视频会把 token 数乘上时间维。
- VLA 还要加入动作 token、状态 token 和语言指令。
- 世界模型训练还要保留未来预测所需的时序信息。
因此高效训练常常不是先换更大模型,而是先问:视觉 token 是否过密,连接器是否能按任务抽取信息,视频帧是否需要全部进入上下文,哪些状态可以放进 latent memory。
三种常见路线
1. Projector:简单直接
把视觉 encoder 输出线性映射到语言模型 embedding 空间。优点是实现简单、训练稳定;缺点是 token 数和信息选择能力较弱,容易把大量视觉 patch 原样交给 LLM。
适合做基础 VLM 对齐,但在长视频、机器人多相机和世界模型训练中,通常还需要更强压缩。
2. Query / Resampler:主动抽取
用少量 learnable query 或 resampler token 从视觉特征中抽取信息。它更像一个可训练的摘要器:不是把所有 patch 都传下去,而是选择后续任务最需要的视觉状态。
这条路线对 VLA 很重要,因为动作决策通常不需要像素级完整重建,却需要保留物体、位姿、可达性、接触关系和目标位置。
3. Cross-attention / Memory:按需读取
让语言或策略 token 通过 cross-attention 从视觉 memory 中读取信息。优点是细节仍可按需访问,缺点是系统复杂度、显存和缓存管理上升。
这更接近长视频和世界模型场景:当前动作只需要一部分视觉证据,但失败恢复和反事实预测可能需要回看更早状态。
一个 token 成本小账
假设桌面机器人使用 4 路相机、16 帧历史,每帧视觉 encoder 输出 个 patch token:
这还没有算语言、动作、proprioception、memory 和未来预测 token。若连接器把每个相机帧压到 32 个任务 token,则视觉侧变成:
序列长度下降约 6 倍,attention、激活显存和通信都会明显下降。但这个收益有前提:压缩后仍要保留目标物、夹爪、接触边界、遮挡前位置和多相机几何关系。否则 token 省下来了,world model 可能失去最关键的动作后果信号。
面向 VLA 的检查点
判断一个视觉连接器是否适合 VLA,不要只看 VQA 分数,还要看:
- 小物体、按钮、抓取点和接触边界是否保留。
- 坐标、方向、左右、相对位置是否稳定。
- 多相机视角是否能对齐到同一动作坐标系。
- 跨帧状态是否能支持速度、遮挡和物体持久性。
- 视觉 token 数是否允许长任务训练。
面向世界模型的检查点
世界模型不只需要“当前图像语义”,还需要“未来可预测状态”。所以连接器要额外回答:
| 问题 | 为什么重要 |
|---|---|
| latent 是否保留运动线索 | 没有速度和接触线索,rollout 很快漂移 |
| latent 是否对动作敏感 | 动作不同但未来一样,说明状态压缩错了 |
| token 数是否支持长 horizon | 视觉 token 过多会让长序列训练成本爆炸 |
| 是否能接入 3D / 深度 / 位姿 | 机器人和自动驾驶常需要几何一致性 |
真实排查案例:视觉 token 省了,抓取开始飘
| 环节 | 观察 |
|---|---|
| 输入症状 | 换成更小 resampler 后,VQA 指标几乎不变,但机器人抓小物体时经常偏 2-4 cm,遮挡后更容易抓空 |
| 指标 | token 数下降、step time 变好;grasp success、contact event accuracy、object permanence 明显下降 |
| Trace / 回放观察 | attention 主要集中在物体大轮廓和语言目标,夹爪附近 crop、接触点和遮挡前位置 token 被压掉 |
| 判断 | 连接器按语义问答压缩是成功的,但按动作和未来预测压缩是失败的 |
| 修复 | 增加 gripper-centric crop token;给接触、目标物和遮挡区域更高采样权重;在评测中加入抓取点、接触事件和 action sensitivity |
| 反例 | 如果任务只是图片问答或静态检索,这种压缩可能完全合理。问题不在 resampler 本身,而在把 VQA 合格误当成 VLA / world model 合格 |
一个实践建议
先建立一个小型连接器评测集:同一批图像/短视频,覆盖问答、定位、动作选择、未来预测四类任务。一个连接器如果只在问答上好,却在动作点、接触关系和跨帧状态上不稳,就不应该直接作为 VLA 或世界模型底座。
读下一页时,可以接 视频表征与长时记忆,看静态视觉 token 如何进一步变成时间状态。
- Title: VLM/VLA:视觉 Tokenizer、连接器与信息瓶颈
- Author: Charles
- Created at : 2026-04-15 09:00:00
- Updated at : 2026-04-15 09:00:00
- Link: https://charles2530.github.io/2026/04/15/ai-files-vlm-visual-tokenizers-and-connectors/
- License: This work is licensed under CC BY-NC-SA 4.0.