
世界模型:RSSM、Dreamer 与规划
世界模型的核心目标,是让智能体拥有一种“在脑中试错”的能力。
与其每次都在真实环境里撞墙、摔杯子、翻车,不如先学一个潜空间动力学,再在里面做想象、评估和规划。
这条路线是最经典的 WM 主线之一。
如果按训练来源划分,它属于“交互轨迹驱动的 latent dynamics / model-based RL 世界模型路线”:从观测、动作、奖励和终止信号中学习潜状态转移,再用 imagined rollout 服务规划或策略学习。它和 生成式模拟与视频世界模型 中的 LingBot-World 路线不同,后者是先继承视频生成先验,再补动作控制、长记忆和因果交互能力。
如果要看 DreamerV3 的单篇训练细节,包括 prediction / dynamics / representation 三类 world model loss、free bits、uniform mix、symlog 和 imagined actor-critic 更新,可以直接看 DreamerV3 论文专题讲解。
如果前面的总览页讲的是“世界模型是什么”,那么这一页讲的是为什么 RSSM 成了经典状态表示,为什么 Dreamer 让世界模型真正和控制连上,以及经典潜空间 WM 和最近 WAM / VAM 路线到底是什么关系。
面向决策的世界模型要回答“如果我这样做,接下来会怎样”。它不仅要预测画面,还要保留会影响奖励、风险、终止和动作选择的信息。视觉上合理但对动作不敏感的未来,对规划帮助有限。
玩游戏前先存档,然后尝试不同路线,看哪条会掉血、哪条能拿奖励。世界模型就是把这种“先在脑中试几条路线”学成模型,减少真实环境里的试错成本。
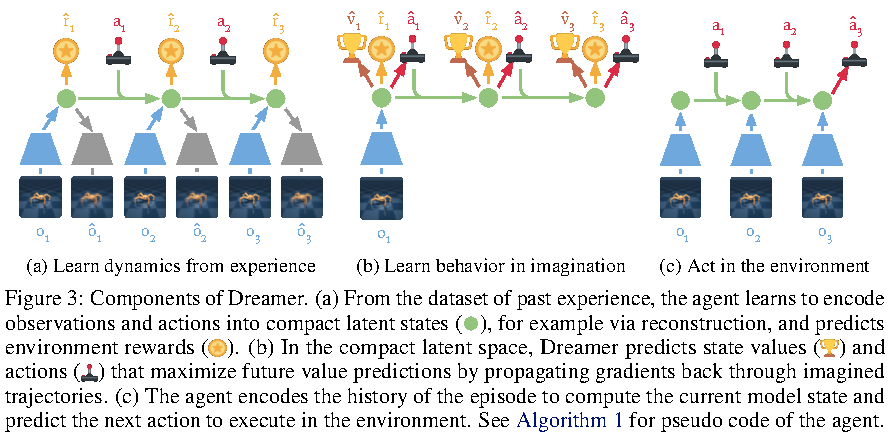
图源:Dream to Control,Figure 3。原论文图意:Dreamer 先从经验数据中把观测和动作编码到 compact latent states 并预测 reward;再在 latent space 中想象 trajectories,训练 action 和 value;最后用真实 episode history 编码当前状态并执行动作。
左边的 learn dynamics from experience 是世界模型训练,中间的 learn behavior in imagination 是把模型当成可微模拟器训练 actor-critic,右边的 act in the environment 是真实执行。核心闭环是:真实经验更新世界模型,世界模型产生 imagined rollout,imagined rollout 更新策略,策略再回到真实环境收集新经验。
1. 统一问题:从观测序列中恢复潜在世界
设环境真实状态为 ,但智能体只能看到观测 ,执行动作 ,获得奖励 。
世界模型希望学习:
这里 是潜在状态,不一定和真实物理状态逐维对应,但它应该足够用于重建当前观测、预测未来演化、评估动作后果,并为策略或规划器提供紧凑状态。
可以把它想象成“环境的内部草图”。
1.1 为什么要学潜状态,而不是直接在像素上规划
因为高维观测太贵,也太不稳定。
如果直接在图像或视频上做多步预测和搜索,会很快遇到维度太高、短时细节占用太多建模容量、rollout 误差传播太快,以及决策真正关心的信息被纹理噪声淹没的问题。
潜状态路线的核心信念是:
并不需要把世界按像素一比一记住,只需要把会影响未来动作选择的信息保留下来。
2. 为什么需要 RSSM
纯随机状态模型容易缺记忆,纯确定性 RNN 又难表达不确定性。
RSSM 的关键是把状态拆成确定性记忆 和随机潜变量 两部分。
常见更新为:
看到当前观测后,再形成 posterior:
这里的直觉很强: 负责“历史记忆”,例如车之前是在左转还是右转; 负责“当前不确定性”,例如前方遮挡后到底有没有行人。
2.1 一个更完整的生成-推断视角
可以把 RSSM 看成两条链:
先验链
给定历史和动作,预测“接下来可能在什么状态”:
后验链
在真的看到观测 后,再纠正这个估计:
这很像人类开车时的心理过程:先根据上一秒和自己的动作预期前方会是什么,真看到新画面后,再把这个预期修正一下。
3. 一个生动例子:雾天开车
自动驾驶在雾天看到前方一团模糊白影时,单帧图像不足以判断那是一辆车尾、一块路牌,还是一团雾反光。
这时:
确定性状态 会利用过去几帧的运动趋势,随机状态 会保留“前方目标类型”的不确定性。
这正是 RSSM 比单纯图像编码更强的地方。
4. 训练目标:序列 ELBO
通常以变分下界训练世界模型。若略去常数项,一个常见目标为:
其中 常表示 continue 或 discount 信号,用于预测 episode 是否终止。
这个式子可以这样理解:重建项要求潜状态保留足够信息,奖励项要求潜状态对决策有用,KL 项要求 posterior 不要偏离 prior 太多,使模型能在没有真实观测时继续 rollout。
4.1 为什么 continue / done 头很重要
很多初学者只盯着观测重建和奖励预测,但 episode 终止或任务失败信号也非常关键。
如果模型不知道“这条 imagined 轨迹其实已经撞墙或任务结束了”,规划器就会在一个错误的未来里继续优化。

图源:Dream to Control,Algorithm 1。原论文图意:Dreamer 交替执行真实环境交互、world model 更新、imagined rollout、actor/value 更新和真实动作执行。
第一条是真实经验流:环境 episode 进入 replay buffer,用来更新 representation、transition、reward 和 continue。第二条是想象经验流:从真实历史编码出的 latent state 出发,在模型里 rollout,再训练 actor/value。Dreamer 的精髓不是某个单独 loss,而是真实数据和 imagined data 之间的交替更新。
5. 为什么 KL 项很关键
如果没有 KL 约束,posterior 可能高度依赖当前观测 ,变成“只有看见真图才会推理”。
那一旦进入 imagined rollout,没有真实观测可用,模型立刻失效。
KL 项强迫 prior 和 posterior 靠近:
这样做的结果是:即使没有真实图像,模型也能凭过去状态和动作在潜空间里继续往前推。
5.1 KL 太强和太弱都会出问题
太弱
posterior 依赖真实观测太重,imagined rollout 失真。
太强
模型会为了满足 prior/posterior 一致性而牺牲表达能力,导致潜状态信息量不足。
这也是很多实现里要调 KL 权重、free bits、KL balancing 和 latent 类型。
6. 离散 latent 与连续 latent
RSSM 经典上既可以用连续 latent,也可以用离散 latent。
6.1 连续 latent
优点是数学上更自然,便于高斯 prior / posterior,优化相对平滑;风险是多模态未来有时表达不够尖锐,容易学到“平均化”状态。
6.2 离散 latent
优点是更适合表示多模态分支,在一些任务上 imagined rollout 更清晰,也更容易和 token 化方法对接;风险是训练技巧更多,量化、采样和梯度近似更复杂。
7. Dreamer:在潜空间里学策略
世界模型学好后,Dreamer 不在真实环境中大规模采样,而是在潜空间里“想象未来”。
给定当前潜状态 ,策略产生动作:
然后世界模型推进:
累计 imagined reward:
并据此更新策略和价值函数。
一个直观比喻
这很像围棋选手先在脑中推演几手,而不是每次都真的把棋子落下。
不同的是,Dreamer 的“脑内棋盘”不是手工规则,而是神经网络学出来的潜空间动力学。
8. Actor-Critic 在潜空间里怎么做
Dreamer 通常同时学习价值函数:
并用 imagined trajectory 估计回报,例如 -return:
这里为了简化记号,可把 理解为潜状态对 的组合表示。
策略优化目标大致为:
这带来两个现实收益:与真实环境交互更省样本,也可以在同一个 learned model 上尝试不同策略。
8.1 Dreamer 真正回答了什么
它回答的不是“世界模型能不能预测未来”,而是:
这个未来预测能不能被直接拿来更新策略。
这正是世界模型和普通生成模型路线的关键分界点。
9. 例子:仓储机器人拐弯避箱
机器人要从货架间穿行,当前前方两米处有一个临时放置的纸箱。
若没有世界模型,它可能必须真的试着左右偏一下,看看会不会擦碰。
有世界模型后,它可以在潜空间里先预测直行会不会撞上、向左是否会卡在转角、向右是否会占用来车通道。
然后再选择最优动作。
10. 规划与策略并不相同
世界模型有两种主要用法:
10.1 学策略
让策略网络直接在 imagined rollout 上优化。
优点是推理快,像端到端控制器。
10.2 做在线规划
给定当前潜状态,显式搜索未来动作序列:
这更像 MPC。
优点是适应新场景更灵活,缺点是在线优化慢。
一个例子:无人机穿门
如果环境每次都不同,只训练固定策略可能不够。这时更合理的是让世界模型先预测不同动作序列的未来轨迹,规划器选出最有希望穿过门框且不撞边缘的动作,只执行前一小段后再重新规划。
11. Dreamer、WAM、VAM 的关系
这条经典路线是最典型的 WM。
它的结构通常是 world model 学潜状态,policy 在潜状态上学,动作生成和世界预测仍然分层。
而最近的 WAM / VAM 路线开始尝试打破这条分层:
WAM更倾向于把动作和未来世界一起建模;VAM更倾向于把视频先验和动作建模绑得更紧。
11.1 为什么经典 Dreamer 仍然重要
因为它给出了最干净的一条基线:world model 是什么,imagined rollout 怎么用,world 和 policy 怎样解耦。
没有这条基线,后面的统一模型很容易显得只是“更大更复杂”,而很难判断它到底多解决了什么问题。
12. RSSM / Dreamer 最怕什么
12.1 视觉上像,动力学上错
一个视频预测模型可能生成得很逼真,但物理规律错了。
例如杯子被推一下后,视频看着很像真视频,但杯子的位移速度和摩擦关系完全不对。
对控制来说,这是致命问题。
世界模型不是做“好看视频”,而是做“决策可用模拟”。
12.2 长时滚动误差累积
如果单步误差为 ,多步 rollout 后误差常会快速放大:
因此很多世界模型在 5 到 20 步内很有用,再长就开始漂。
12.3 奖励预测不准
有时观测重建很好,但奖励模型很差。
例如机器人在桌面上移动积木,世界模型看起来能重建积木位置,却无法准确判断“是否已经对齐目标区域”。
这会导致策略优化方向错掉。
12.4 分布外动作
训练数据里从没出现过“高速急转弯”,但规划器在潜空间搜索时可能提出这种动作。
这时世界模型的预测常不可信。
13. 三个具体应用场景
13.1 游戏智能体
这是最经典场景。
游戏像素输入高维,但规则相对稳定,很适合先学潜空间,再在潜空间里想象未来。
13.2 自动驾驶
世界模型可用于预测周围车辆未来轨迹、模拟不同驾驶决策的结果、评估潜在风险。
但这里对罕见事件和安全边界要求极高,因此不能只依赖“平均意义上的预测对”。
13.3 机器人操作
世界模型可以帮助判断夹爪是否即将碰撞杯沿、拉抽屉时是否会卡住、推箱后是否会挡住下一步抓取路径。
14. 一个实用判断框架
如果你在看一篇 RSSM / Dreamer 风格论文,最值得追问的是:潜状态到底保留了什么,imagined rollout 能稳定多长,奖励和终止信号是否真的可读,world model 对策略到底提供了什么增益,以及这种增益来自更好的世界预测,还是只是更强的策略训练技巧。
15. 小结
RSSM 提供了经典世界模型的状态骨架:记忆加不确定性。
Dreamer 则把这套骨架真正用于控制:先在潜空间里想象,再用想象轨迹优化策略。
它们共同构成了最经典的 WM 主线,也是理解后续 WAM / VAM 路线时最重要的参照系。
快速代码示例
1 | def dreamer_actor_update(world_model, actor, z, h, horizon=15): |
这段代码抽象了 Dreamer 的 actor 更新思路:不在真实环境里采样,而是在世界模型的隐空间 rollout 上估计长期回报并优化策略。好处是样本效率高,但前提是动力学与奖励头的偏差要可控。
工程收束
RSSM / Dreamer 的价值不只在重建画面,而在 belief state、latent rollout、planner 接口、reward readout 和不确定性是否能共同支撑规划。验收时要拆分表征、动力学和规划评测,保留反事实测试,让不确定性进入回退逻辑;世界模型一旦被策略使用,视频质量就不能替代闭环效果。
- Title: 世界模型:RSSM、Dreamer 与规划
- Author: Charles
- Created at : 2026-05-07 09:00:00
- Updated at : 2026-05-07 09:00:00
- Link: https://charles2530.github.io/2026/05/07/ai-files-world-models-rssm-dreamer-and-planning/
- License: This work is licensed under CC BY-NC-SA 4.0.