
世界模型:模拟器、反事实与合成 Rollout
世界模型一旦不仅用于预测未来,而开始指导下一步收什么数据、在哪些场景做验证、如何构造高价值训练样本,就会自然走向模拟器、反事实生成和合成 rollout 数据。这条路线的核心不是“伪造更多样本”,而是让 imagined data 服务长尾风险覆盖、失败恢复、planner warmup、策略改进和数据引擎闭环。
合成 rollout 的价值不在于“数据更多”,而在于能围绕真实世界难收集的边界做密集试验:差一点撞、差一点抓稳、差一点选错工具。这些样本最贵,也最能训练恢复和风险判断。
世界模型生成的未来可能平均合理,但边界错误。若直接把错误 rollout 喂回训练,策略会越来越擅长利用模型幻觉。合成数据应先经过规则、一致性、多模型分歧、人工或经典模拟器门禁,再决定进入训练还是只做评测。
飞行员可以在模拟器里练紧急情况,但前提是模拟器不能在关键边界上胡编。世界模型合成 rollout 也一样:越接近事故边界,越需要额外校验,而不是因为画面合理就直接进训练集。
世界模型为什么会模拟器化
一旦模型能够学习:
它就不只是预测器,而接近一个可条件查询的环境模拟器。你可以问它:如果向左绕开会怎样,如果多等一秒会怎样,如果换抓取姿态会怎样,如果障碍位置变了会怎样。
模拟器的核心价值是安全、廉价、可重复地“先试一遍”。世界模型把这件事从手写物理规则扩展到真实数据里的感知噪声、遮挡、多主体互动和行为先验。
与经典模拟器的关系
世界模型模拟器和经典物理模拟器不是替代关系。
| 类型 | 擅长 | 局限 |
|---|---|---|
| 经典模拟器 | 几何、动力学、可控参数、可重复实验 | 难覆盖真实感知噪声和复杂行为分布 |
| 世界模型 | 真实数据先验、遮挡、交互、反事实生成 | 边界可能幻觉,物理一致性不保证 |
| 混合系统 | 结构约束 + 真实先验 | 工程复杂,门禁要求高 |
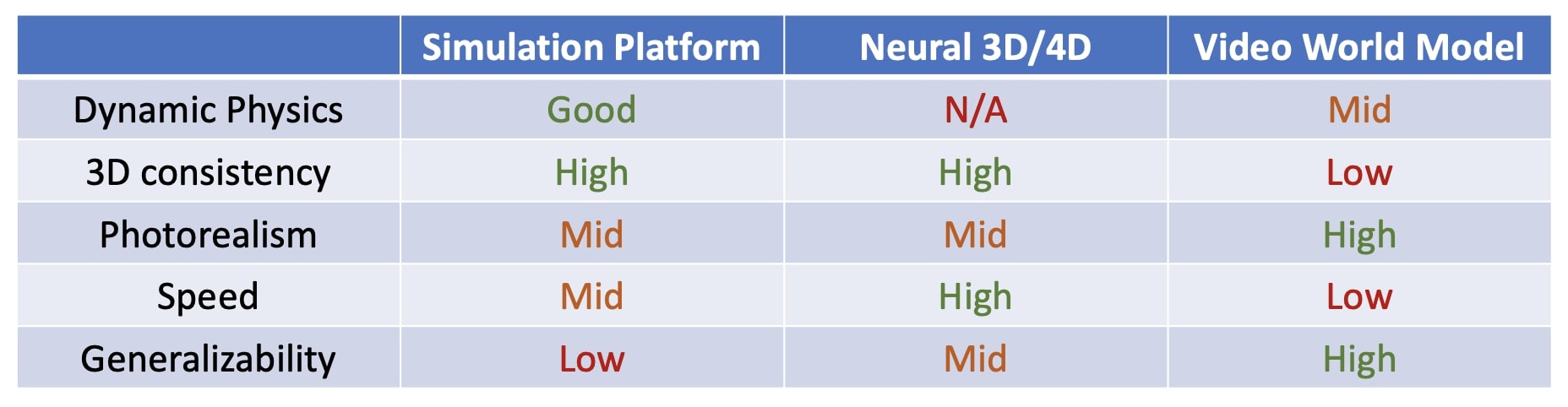
图源:Towards Video World Models,Figure 9。原论文图意:对比不同 simulation approaches 如何从真实世界、重建、生成式模型和交互数据中组织模拟能力。
这张图适合帮助读者判断 synthetic rollout 的可信度:它来自真实日志、经典仿真、3D 重建,还是纯生成模型?每多一层生成,就多一层偏差来源。高风险样本最好进入“评测/人工复核池”,而不是直接混进训练集。
很多现实系统更适合混合:经典模拟器提供结构约束和可控场景,世界模型提供真实感、行为先验和难以显式建模的分布。
反事实生成
反事实生成问的是:如果只改变某个因素,其余条件尽量保持不变,未来会怎么改?
例子包括:
- 同样桌面场景,把杯子位置偏 5 厘米;
- 同样路口,把行人启动时间提前 0.7 秒;
- 同样网页流程,把按钮文本改掉;
- 同样工具调用,把一条约束改成不同数值。
反事实数据值钱,是因为真实数据最稀缺的部分往往是接近失败边界、差一点成功或差一点出事故的样本。反事实让系统能围绕这些高价值边界做更密集学习。
合成 Rollout 的用途
| 用途 | 目标 |
|---|---|
| Planner warmup | 真实交互前给 planner 或 value head 一个初始形状 |
| Risk head 强化 | 增加 near-miss 与事故边界识别 |
| 恢复策略训练 | 合成接近失败但仍可救回的轨迹 |
| 数据平衡 | 补全真实数据中稀缺边界 |
| Stress testing | 构造专项验证集,不一定进入训练 |
| 主动采样 | 帮助决定下一批真实采集区域 |
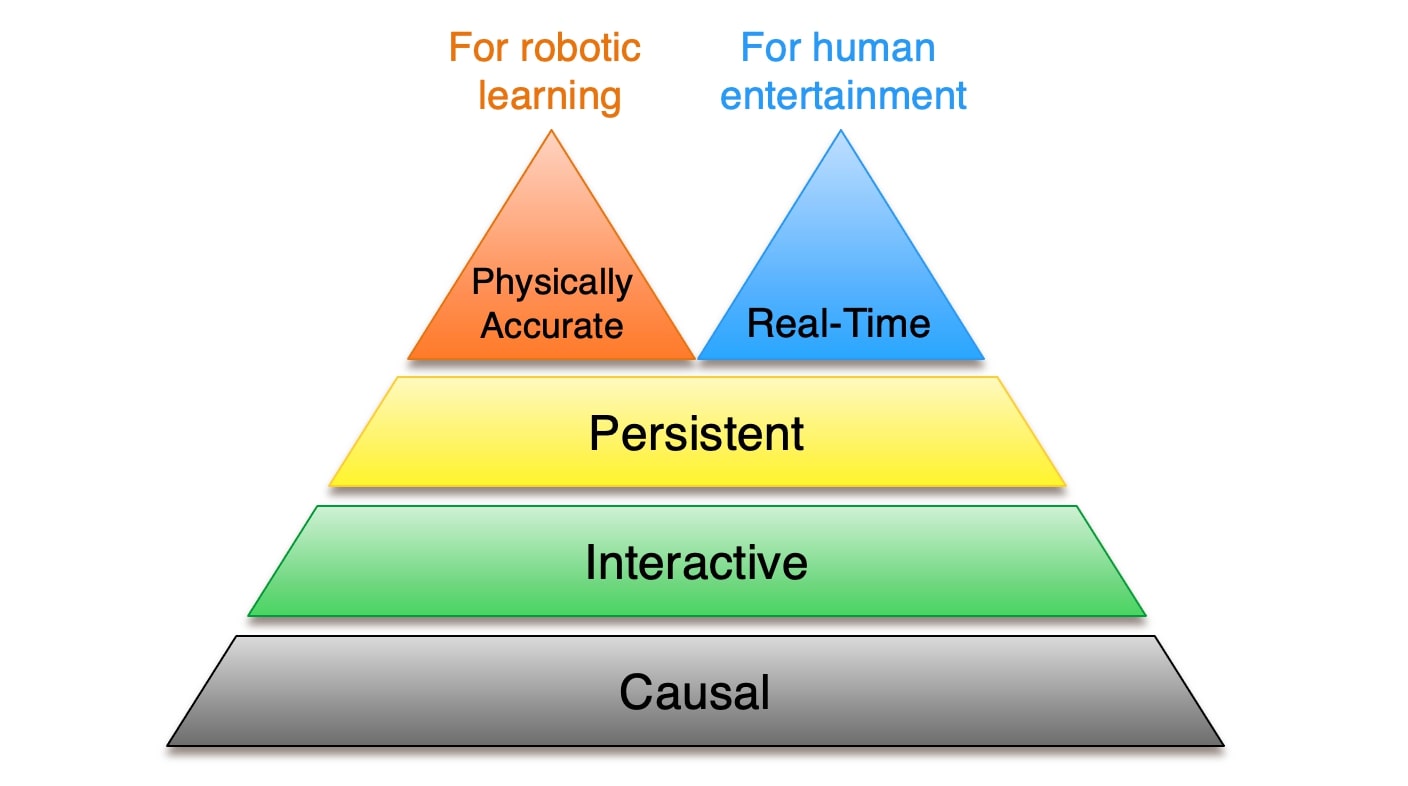
图源:Towards Video World Models,Figure 8。原论文图意:把 video world model 能力按层级组织,从短期视觉预测逐步走向长期、一致、可交互、可用于决策的世界模拟。
低层能力可能只说明模型会续写画面;高层能力才涉及长期一致性、动作可控性、交互性和决策价值。把合成 rollout 用于训练前,先问它属于哪一层:只适合做视觉增强,还是能作为风险反事实,还是足够可靠到能影响 planner 或 policy。
机器人和自动驾驶尤其适合这类数据,因为真实边界试错昂贵且危险。抓取偏差、碰撞边界、行人启动、旁车礼让、施工锥桶位置,这些都很难靠真实主动试错系统覆盖。
最大风险是错误地自信
Imagined data 最危险的地方,不是它“不真实”,而是它可能在最关键的边界不真实。
常见风险包括:
- 平均上合理,边界上错误;
- 视频很真,但动力学错;
- 风险事件被平滑化;
- 模型偏差被重复蒸馏;
- planner 学会利用模型漏洞;
- 合成数据污染真实评测。
如果没有门禁,系统只会越来越自信地学习自己的幻觉。因此 imagined data pipeline 的核心不是“怎么生成更多”,而是哪些能进训练、哪些只能做弱监督、哪些只进入验证集、哪些必须人工或经典模拟器复核。
门禁流程
一个更稳妥的流程是:
- candidate pool:世界模型生成候选反事实或 rollout;
- consistency check:用几何、物理、工具规则或程序约束检查;
- disagreement filter:用 ensemble 或多模型分歧筛掉不可靠样本;
- human / simulator gate:高风险样本交由人工或经典模拟器复核;
- training export:按用途进入监督、risk ranking、评测或人工采样队列。
不同置信度样本应进入不同用途。高置信 rollout 可做辅助监督,中置信样本可做排序或风险训练,高分歧样本更适合送人工或真实采集。
评测清单
评估合成 rollout 数据时,建议看:
- 反事实变化是否局部且可解释;
- 动作条件是否真的改变未来分支;
- 物理、几何、工具或业务规则是否一致;
- 进入训练后是否提升目标 bucket;
- 主分布和真实数据评测是否退化;
- 合成数据是否被模型或评测泄漏;
- 人工/模拟器门禁通过率和拒绝原因。
还应保留“只评测不训练”的合成集。很多 imagined rollout 不适合直接进入训练,但很适合做 stress test:例如同一个失败片段周围的动作扰动、同一个驾驶场景下的参与者反应变化、同一个机器人接触状态下的恢复动作比较。把这类样本直接混入训练,可能污染分布;但把它们作为固定评测集,可以持续检验模型是否真的理解关键边界。
合成数据还需要版本化。生成模型版本、prompt 或条件、门禁规则、人工复核结果、最终用途都应记录下来。否则一旦模型能力变化,团队很难判断收益来自更好的世界模型、更宽松的门禁,还是评测集被合成数据间接污染。
更稳的组织方式是把合成 rollout 分成训练池、评测池、人工复核池和真实采集候选池。四个池子的准入标准不同,不能混用。尤其是评测池,一旦被训练数据间接污染,就会让世界模型看起来越来越强,但真实闭环并没有同步提升。
合成数据越多,越需要清楚标记来源和置信度,避免后续复盘时把模型想象误当真实经验。
这也是合成数据治理的底线。
世界模型合成数据的价值不在数量,而在能否稳定补齐真实系统最稀缺、最昂贵、最接近能力边界的数据。
- Title: 世界模型:模拟器、反事实与合成 Rollout
- Author: Charles
- Created at : 2026-05-09 09:00:00
- Updated at : 2026-05-09 09:00:00
- Link: https://charles2530.github.io/2026/05/09/ai-files-world-models-simulators-counterfactuals-and-synthetic-rollouts/
- License: This work is licensed under CC BY-NC-SA 4.0.