
论文专题讲解:Lance:统一多模态模型,为什么对世界模型有启发
Lance 不是 Dreamer 那类 model-based RL 世界模型,也不是 LingBot-World 那类动作条件交互模拟器。它值得放进世界模型专题,是因为它回答了另一个底层问题:如果一个模型既要理解图像/视频,又要生成和编辑图像/视频,语义 token、视觉 latent、干净条件和带噪目标应该怎样放进同一个上下文?
世界模型最终也会遇到类似问题。planner 需要抽象语义状态,simulator 需要细节和运动,解释模块需要语言,生成模块需要连续视觉 latent。Lance 提供的是“统一多模态状态层”的结构样板,而不是完整可交互环境。
Lance 到底统一了什么
很多多模态系统把理解和生成拆成两条路线:理解模型用 ViT/LLM 做问答、OCR、推理;生成模型用 diffusion/flow 在 VAE latent 上生成图像或视频。简单拼接会有冲突:理解需要高层语义,生成需要低层连续细节;语言 next-token loss 和视觉 velocity/diffusion loss 的优化动态也不同。
Lance 的做法是:
1 | shared interleaved multimodal context |
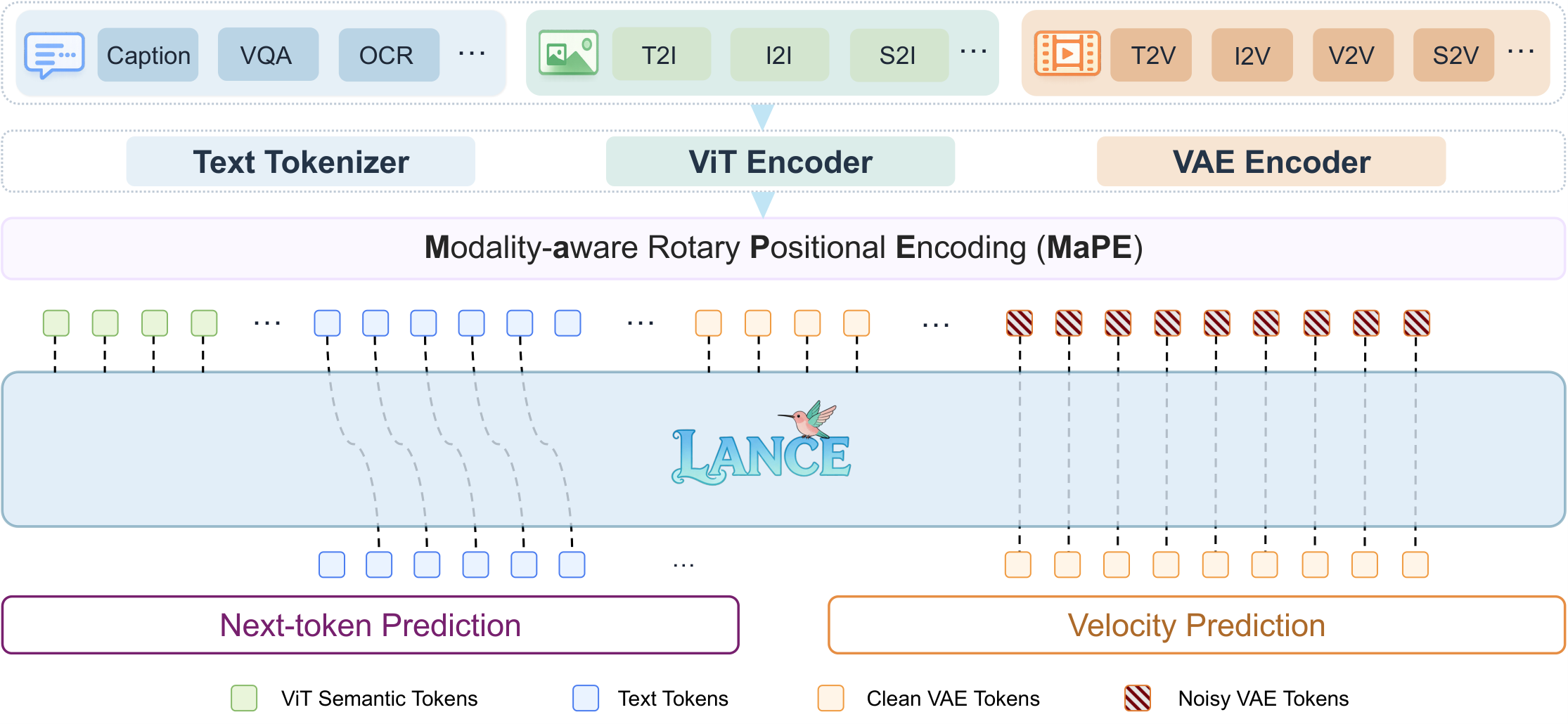
图源:Lance: Unified Multimodal Modeling by Multi-Task Synergy,Figure 6。原图表达:X2T、X2I、X2V 等任务被编码进 MaPE 增强的统一多模态上下文;dual-expert backbone 在共享上下文上做 generalized 3D causal attention,并分别通过 LM head 做 next-token prediction、通过 flow head 做视觉 latent velocity prediction。本站读法:上半部分看任务如何进入同一上下文,下半部分看理解和生成为什么分 expert。
从世界模型角度看,Lance 的关键不是“能做很多任务”,而是把不同角色的视觉信息放进同一个序列后,还显式区分它们的用途:
| 状态角色 | Lance 中的形式 | 对世界模型的启发 |
|---|---|---|
| 语义状态 | text tokens + ViT semantic tokens | 让模型知道对象、关系、任务和可解释语义 |
| 生成状态 | clean/noisy VAE latents | 让模型保留像素细节、运动和可生成未来 |
| 共享上下文 | interleaved sequence | 让理解、编辑、生成互相传递条件 |
| 角色标识 | MaPE + segment attention | 防止条件 token、目标 token、语义 token 混在一起 |
统一上下文怎么写
Lance 把一个样本写成 interleaved multimodal sequence:
这里 是整条多模态上下文, 表示把不同块串接起来, 是文本 token, 是语义视觉 token, 是干净 VAE 条件 latent, 是带噪生成目标 latent。
文本块和视觉块分别包上边界 token:
这行式子读起来很朴素:不要只把所有 token 乱塞进一个序列,而要告诉模型每段 token 从哪里开始、到哪里结束、属于文本还是视觉。对世界模型来说,这对应未来可能出现的 state/action/reward/future target 分块。
为什么要双 expert
Lance 用两个 expert 处理同一个上下文。
| Pathway | 主要输入 | 输出 | Objective |
|---|---|---|---|
| text + ViT semantic tokens | text tokens | autoregressive next-token prediction | |
| VAE latent tokens + shared context | visual latent velocity | flow matching / velocity prediction |
理解侧 loss 是:
这里 是要预测的第 个文本 token, 是多模态上下文。公式读法是:理解 expert 根据图像、视频和文本上下文预测下一文本 token,训练压力来自语言/理解任务。
生成侧先把干净 latent 和噪声 插值:
这里 是从 0 到 1 采样的连续时间, 是噪声到干净 latent 之间的中间点。生成 expert 要预测从 走向 的 velocity:
这行式子表达的是 flow matching:模型预测的 velocity 要接近真实方向 。它不是语言 token loss,而是视觉 latent 的连续生成目标。
总目标是:
和 控制理解 loss 与生成 loss 的权重。这里的工程判断很重要:Lance 不强迫语义理解和视觉生成共享同一条参数路径,而是在同一上下文里通信、在不同 expert 里优化。这对世界模型也很有启发:给 planner 的状态要抽象稳定,给 simulator 的状态要保留细节,二者可以共享上下文,但不一定该共用同一表示和同一 loss。
MaPE:告诉模型 token 角色不同
普通 3D-RoPE 会按 给视觉 token 编码。但 Lance 的同一上下文里可能同时出现 ViT semantic tokens、clean VAE condition tokens、noisy VAE target tokens。它们可能来自同一帧、同一空间位置,但角色完全不同。

图源:Lance,Figure 7。原图表达:MaPE 给不同 modality token group 在 temporal dimension 上加入固定 offset,使 noisy VAE、ViT semantic 和 clean VAE tokens 在全局位置空间中可区分。本站读法:位置不只表示“在哪里/何时”,还要帮助模型区分“这是条件、语义还是目标”。
MaPE 的做法可以写成:
这里 是原始 3D 位置, 表示第 个 token group, 是组间偏移。读这行公式时,重点是每组视觉 token 在时间轴上被错开,从而避免“同一位置但角色不同”的 token 互相串台。
世界模型里也会有类似问题:past observation、current state、candidate action、future target、risk token 可能都带时间或空间位置。如果不显式标出角色,模型可能把条件和目标混淆,把观测和想象混淆。
训练路线:多任务协同不是把数据混在一起
Lance 的训练分 PT、CT、SFT、RL 四阶段。
| 阶段 | 主要目的 | 对世界模型的启发 |
|---|---|---|
| PT | 用大规模 image-text/video-text 建立理解和生成底座 | 先学视觉和语义基础,不急着塞所有任务 |
| CT | 加入 interleaved understanding、generation、editing、subject-driven data | 多任务信号可以帮助对象、身份和关系保持 |
| SFT | 用高质量数据提升指令遵循、编辑准确性和一致性 | 后期数据质量比原始规模更重要 |
| RL | 用 GRPO 优化图像生成中的文字和图文约束 | reward 可以接入生成,但这里还不是环境 reward |
注意最后一点:Lance 的 RL 主要针对 image generation,reward 使用 PaddleOCR 等信号检查 text rendering 和 prompt adherence。它不是视频物理 reward,也不是动作条件世界模型里的环境 reward。
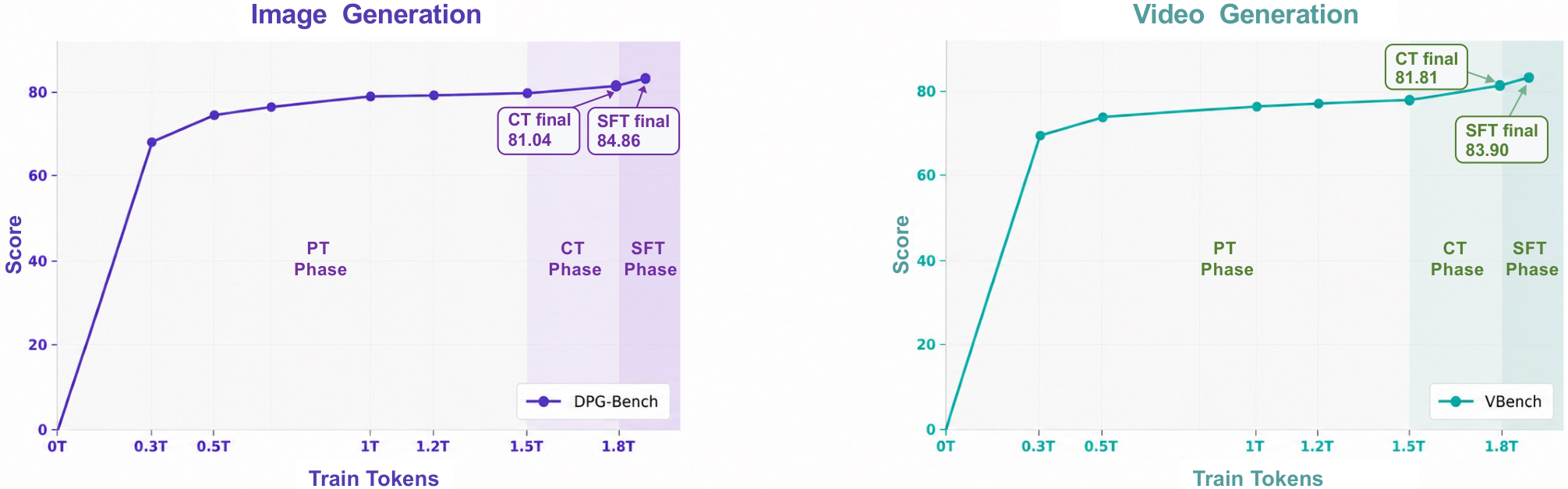
图源:Lance,Figure 13。原图表达:image generation 的 DPG-Bench 和 video generation 的 VBench 随训练 token 增加的 scaling behavior。本站读法:图像能力早期提升更快,视频能力因为时序一致和动态建模更难,收益持续得更久。
这张图的启发是:视频能力不是结构一换就自然出现。更长训练、更丰富任务、更细的数据 schedule,都会影响时间一致、主体身份和动作顺序。
实验证据支持什么
Lance 的项目页和论文报告了 GenEval、DPG-Bench、GEdit-Bench、VBench、MVBench 等结果。最稳的读法是:Lance 证明 3B activated parameters 的统一模型可以在理解、生成、编辑之间获得较强协同,尤其在开源 unified models 对比中表现亮眼。
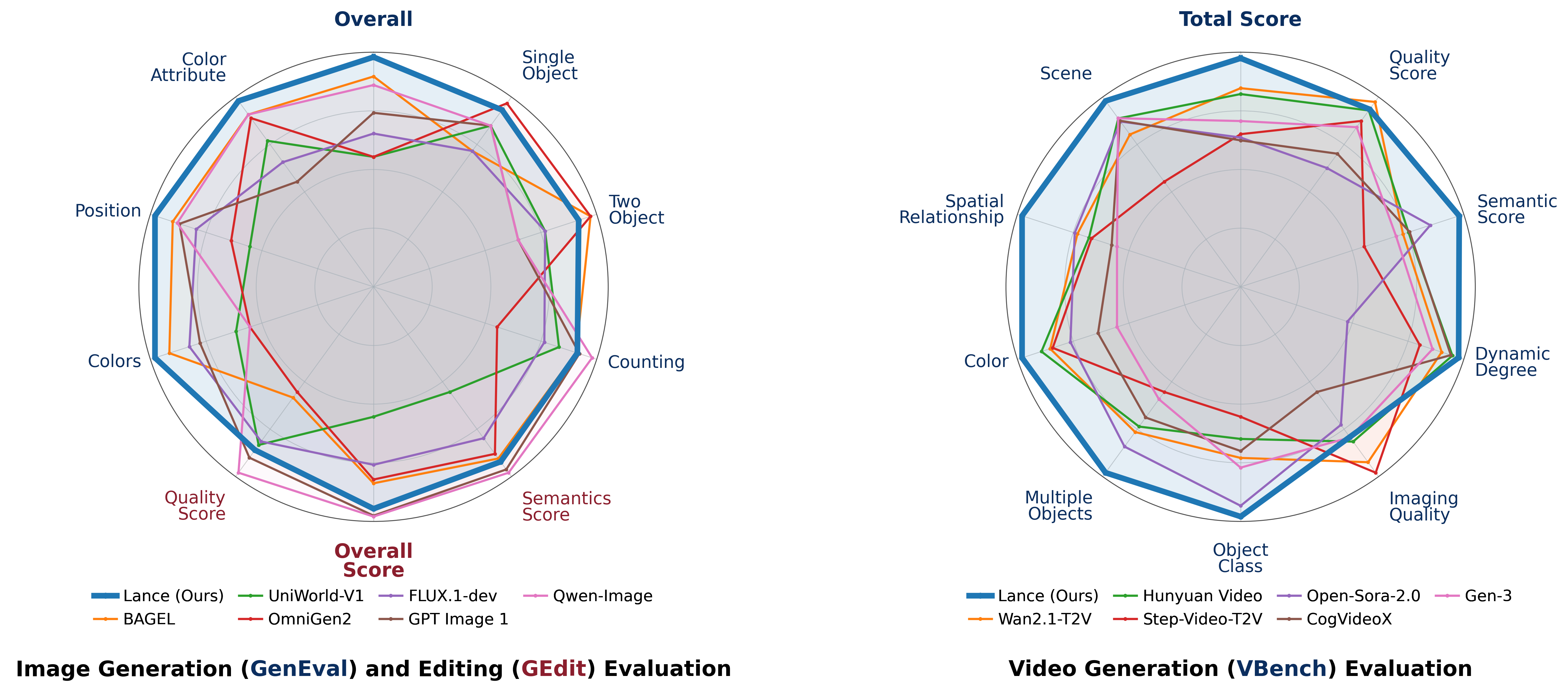
图源:Lance project page / paper Figure 1。原图表达:Lance 与代表性统一模型和专用模型在 image generation、image editing、video generation、video understanding 上的 radar chart 对比。本站读法:这证明跨任务统一训练有效,但 radar chart 不等于闭环控制评测。
论文里最值得世界模型读者关注的是 cross-task data ablation:适量 understanding data 和 multi-task generation data 会改善 generation 与部分 understanding 指标。这说明 caption、VQA、OCR、grounding、editing、subject-driven generation 这类辅助任务,可能提升模型对对象身份、关系、文本约束和场景语义的保持能力。
但边界同样明确:这些 benchmark 主要测视觉质量、语义对齐、编辑能力和视频理解,不测“同一历史下不同动作会产生怎样不同未来”。一个模型 VBench 很高,不代表它知道左转、右转、停止、加速分别会造成什么后果。
和世界模型的距离
如果把 Lance 改成更强的世界模型,还缺这些变量:
| 缺口 | 为什么重要 |
|---|---|
| Action-conditioned dynamics | 世界模型必须预测动作后果,而不只是按 prompt 生成视频 |
| Causal online rollout | 交互系统不能依赖未来 chunk,也要能逐步接收动作 |
| Persistent memory | 长任务里对象离开视野后仍要保持身份和位置 |
| Reward/risk heads | planner 需要比较候选未来的价值和风险 |
| Closed-loop validation | benchmark 高分不保证 agent 任务成功 |
所以 Lance 更像“统一状态层”和“多任务训练配方”。它可以启发未来世界模型怎样组织 text、semantic visual tokens、VAE latents、editing targets 和 generation targets;但还没有补上 action、reward、risk、memory 和 online rollout。
局限与阅读边界
第一,Lance 不是动作条件世界模型。论文没有证明 fixed history 下不同动作会产生可验证的未来分叉。
第二,RL 范围较窄。它用 GRPO 优化图像文字渲染和图文约束,不覆盖视频动力学、物理一致性或任务成功率。
第三,训练初始化表述要谨慎。摘要强调 unified model 和 staged multi-task training,项目页说是 research artifact;论文实现细节又使用 Qwen2.5-VL 3B 初始化理解相关组件、Wan2.2 3D causal VAE 作为生成 encoder。读它时不要理解成“完全随机从零训练所有模块”,也不要理解成“只是简单微调现成 VLM”。核心贡献在统一上下文、双路径和多任务 recipe。
第四,官方项目页也提醒 released checkpoint 不是 polished product model,输出质量会随 prompt、分辨率、时长、motion complexity 和 editing scenario 波动。
外部精读
- Lance 论文:完整方法、训练配方、ablation 和 benchmark。
- Lance project page:官方 demo、模型说明和实验表。
- 项目 PDF:查看 Figure 6、MaPE、training schedule 和 ablation 细节。
阅读结论
Lance 最值得带走的不是某个 benchmark 分数,而是一个结构判断:统一多模态模型不必把理解和生成硬塞进同一种 token、同一条路径。语义 token、VAE latent、干净条件和带噪目标可以共处一个上下文;理解和生成可以共享上下文但走不同 expert;MaPE 这类角色感知位置编码能减少异构视觉 token 混淆。
对世界模型来说,Lance 是底座结构,不是终点。真正的交互世界模型还要接动作条件、因果 rollout、长期记忆、reward/risk 和闭环评测。把这个边界看清,Lance 才会从“又一个统一多模态模型”变成一篇有用的世界模型结构参考。
- Title: 论文专题讲解:Lance:统一多模态模型,为什么对世界模型有启发
- Author: Charles
- Created at : 2026-06-01 09:00:00
- Updated at : 2026-06-01 09:00:00
- Link: https://charles2530.github.io/2026/06/01/ai-files-paper-deep-dives-world-models-lance/
- License: This work is licensed under CC BY-NC-SA 4.0.