
clustering-analysis
聚类分析
聚类分析的概念与建模
聚类分析的概念
聚类(Clustering):
-
聚类是一个将数据集划分为若干组(class)或(cluster)的过程,并使得同一个组内的数据对象具有较高的相似度;而不同组中的数据对象是不相似的。
-
相似或不相似是基于数据描述属性的取值来确定的,通常利用各数据对象间的距离来进行表示(相似性系数)。
-
聚类分析尤其适合用来探讨样本间的相互关联关系从而对一个样本结构做一个初步的评价。
聚类技术通常又被称为无监督学习,与监督学习不同的是,在簇中那些表示数据类别的分类或者分组信息是没有的。 因此,聚类是观察式学习,而不是示例式学习。
聚类分析的分类及作用
聚类分析有两种:一种是对样品的分类,称为Q型,另一种是对变量(指标)的分类,称为R型。
在实际使用时,要注意聚类分析前一定要对数据进行标准化处理(SPSS处理)以去除量纲对结果的影响。使用时的常见套路为首先使用R类聚类分析来选择部分分析变量(降维),之后使用Q类聚类分析对样本进行分析。
聚类分析的建模
聚类分析的作用
-
聚类分析可以应用在数据预处理过程中,对于复杂结构的多维数据可以通过聚类分析的方法对数据进行聚集,使复杂结构数据标准化。
-
聚类分析还可以用来发现数据项之间的依赖关系,从而去除或合并有密切依赖关系的数据项。聚类分析也可以为某些数据挖掘方法(如关联规则、粗糙集方法),提供预处理功能。
聚类分析适用于国赛中那类分类分组的问题
R型聚类分析的主要作用
(1) 不但可以了解个别变量之间的亲疏程度,而且可以了解各个变量组合之间的亲疏程度。
(2) 根据变量的分类结果以及它们之间的关系,可以选择主要变量进行Q型聚类分析或回归分析。
Q型聚类分析的主要作用
(1) 可以综合利用多个变量的信息对样本进行分析。
(2) 分类结果直观,聚类谱系图清楚地表现数值分类结果。
(3) 聚类分析所得到的结果比传统分类方法更细致、全面、合理。
样品间的相似度量—距离
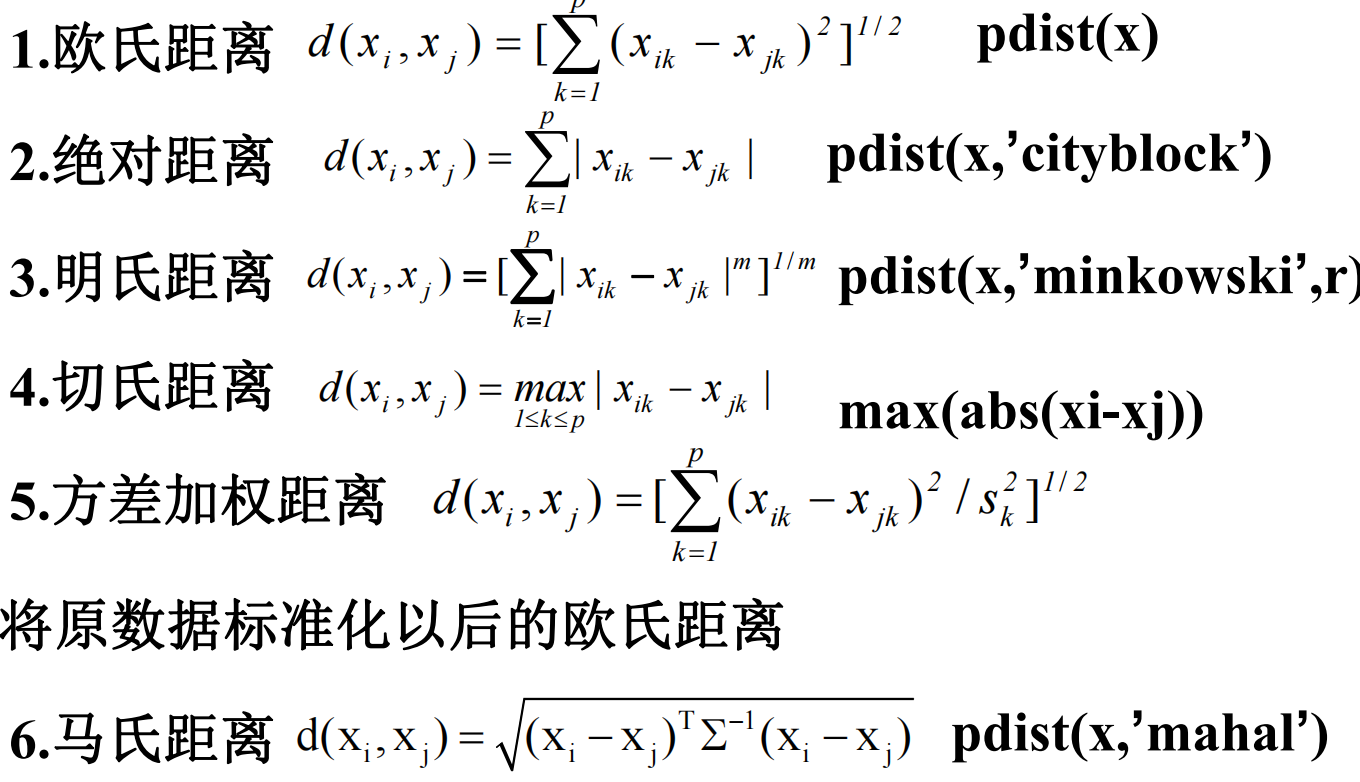
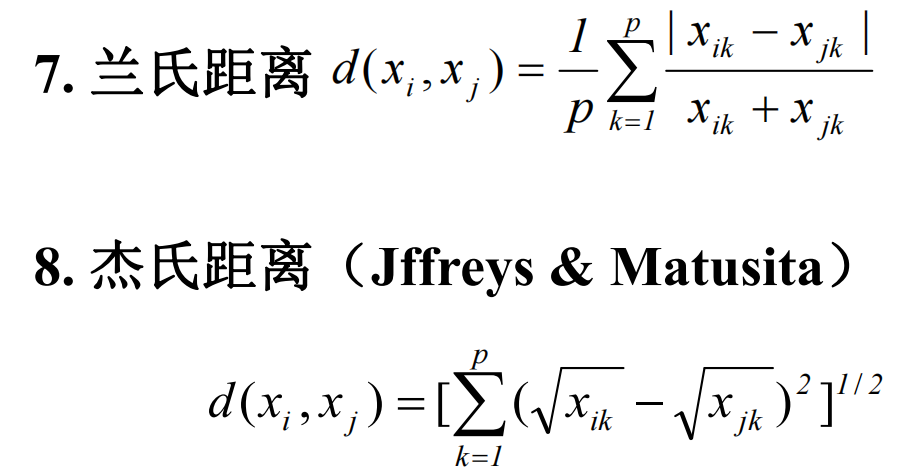
变量间的相似度量——相似系数



类间距离

MATLAB代码示例
聚类分析主要过程
将数据展绘
1 | %聚类分析主要过程 |
利用不同的算法进行带入分析
高斯混合聚类代码
1 | %高斯混合聚类代码 |
K均值聚类算法
1 | %K均值聚类算法 |
分层聚类算法代码
1 | %分层聚类算法代码 |
K-means聚类算法
KMeans的核心目标是将给定的数据集划分成K个簇(K是超参),并给出每个样本数据对应的中心点。(和上面k均值算法的调用是同理,但这个代码可以直接分成k个簇)
1 | function [Idx, Center] = K_means(X, xstart) |
- Title: clustering-analysis
- Author: Charles
- Created at : 2023-09-02 09:26:16
- Updated at : 2023-09-04 12:43:00
- Link: https://charles2530.github.io/2023/09/02/clustering-analysis/
- License: This work is licensed under CC BY-NC-SA 4.0.


